
I remember exactly when I realized we were confusing deployment with release.
It was a Friday afternoon (of course). We had just finished developing an important new feature for our product. The code had been reviewed, tested, and approved by QA. There was pressure to push it to production. So we deployed it.
Minutes later, the problems started.
The feature wasn’t fully validated for every scenario. Some users began reporting unexpected behavior. A rollback became our only option. And, as it often happens, rollbacks are never as simple as they sound — database migrations had already run, other changes were bundled in the same deployment, and small dependencies nobody remembers suddenly become very relevant.
That’s when it became clear to me: the problem wasn’t the quality of the feature. It was how we were delivering it.
We were stuck in an “all or nothing” model. Either the functionality went live for everyone, or it didn’t go live at all. There was no middle ground. No fine-grained control. No safe way to test in production with limited impact.
That’s when I started diving deeper into Feature Flags.
The idea felt almost too simple to solve such a big problem: introduce a control layer between the code running in production and the actual release of the functionality to users.
But the more I studied — and especially once I started applying it — the more I realized that Feature Flags are not just a technical detail. They fundamentally change the way you think about deployment, release management, risk mitigation, and even product experimentation.
In this article, I want to share what I’ve learned about Feature Flags, why they’re so powerful, and also the precautions you need to take to avoid turning this solution into a new source of complexity.

What Are Feature Flags (in Practice)
After that incident, I started looking for a way to clearly separate two things: deploying code to production and releasing a feature to users.
That’s when I truly understood, in practical terms, what Feature Flags are.
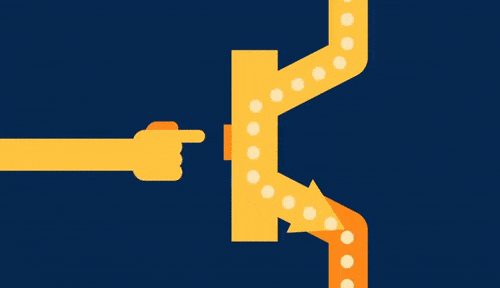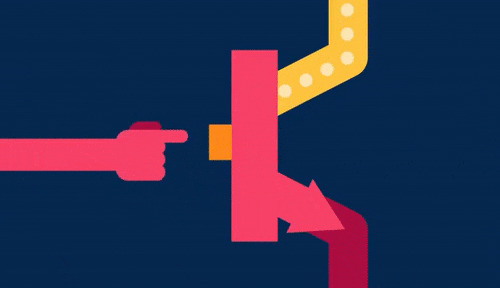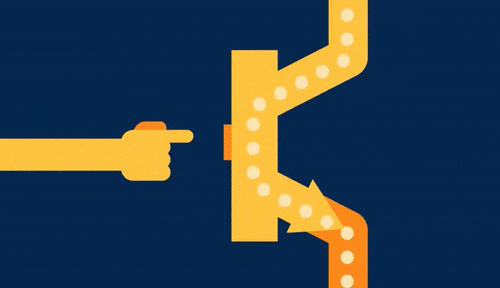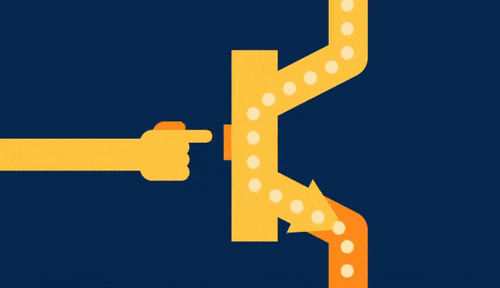
Simply put, a Feature Flag is a mechanism that allows you to enable or disable a feature at runtime, without requiring a new deployment.
In practice, it’s like placing a switch inside your code.
Instead of assuming that once the code is in production the feature is automatically live for everyone, you introduce a control layer:
In this simple example, the new dashboard is already deployed. The code is running in production. But what determines whether users see it or not is the flag.
That changes everything.
With Feature Flags, you can:
- Deploy unfinished functionality (as long as it’s protected by a flag)
- Release features only to internal users
- Enable it for 5% of your user base
- Instantly disable it if something goes wrong
In other words, deployment stops being a high-risk moment and becomes just a technical step.
The business decision — when to release, who should receive it, and at what pace — becomes a separate layer of control.
At its core, Feature Flags are about this:
Decoupling the act of shipping code from the act of exposing functionality to users.
Simple in theory. Transformative in practice.

Types of Feature Flags (Quick Overview)
Not every Feature Flag serves the same purpose. Over time, I realized that classifying them helps a lot — especially to avoid turning your codebase into a mess.
Here are the main types, in a straightforward way:
1️⃣ Release Toggles
These are the most common ones.
They are used to gradually roll out new features.
You deploy the feature, but control when it becomes active — whether for everyone, a specific group, or progressively over time.
This is the type that directly solves the “deploy ≠ release” problem.
2️⃣ Experiment Toggles
Used for A/B testing and experimentation.
They allow you to expose different versions of a feature to different user groups and measure impact on metrics like conversion, retention, or engagement.
At this point, the flag stops being just a technical tool and becomes a product strategy asset.
3️⃣ Ops Toggles
These are operational flags.
They control critical runtime behavior, such as:
- Disabling an external integration
- Reducing traffic to a specific service
- Enabling a fallback or contingency mode
These are especially valuable during incidents.
Understanding these types helps you treat each flag according to its purpose — because each one has a different lifecycle and impact on your system.
Deploy Is Not Release
If there’s one thing Feature Flags changed for me, it’s how I think about risk.
Before, every deployment carried tension. Even small changes felt bigger than they actually were, because once something reached production, it was immediately exposed to everyone. There was no safety net — just confidence and hope.
Feature Flags introduced control.
They allowed me to ship code earlier, test in real environments with smaller audiences, and react quickly when something didn’t behave as expected. More importantly, they helped separate technical delivery from business decisions. Engineering could deploy continuously, while product could decide when and how to release.
But there’s an important caveat: Feature Flags require discipline.
If you don’t remove old flags, document their purpose, and define ownership, they can easily become hidden technical debt.
Used correctly, though, they represent a shift in engineering maturity. They encourage progressive delivery, safer experimentation, and more resilient systems.
Today, I don’t see Feature Flags as just a conditional statement in the code.
I see them as an architectural decision — one that gives teams more confidence to move fast without breaking everything.